3.C. Reference: Architecture Recommendations
The following documentation is a recommendation when considering to deploy Cradle to the cloud. The main understanding of this server architecture is one server per service. We don’t want to put the entire LAMP/LEMP stack in one server on purpose to understand how service performs.
3.C.1. Hardware Components
- Application Server
- Database Cluster
- Cache Server
- Index Server
- Worker Server
- Queue Server
- Proxy Server
- Logs Server
- Monitoring Server
Application Server
Application server acts as the initiating connector between all of the components. This houses the framework in which responses are generated based on the request type for every kind of user.
Recommendations
A load balancer is recommended to evenly distribute traffic between all application servers per region. A redundancy strategy should include the replication of the entire Application Layer.
| Cores | 1 |
| Memory (GB) | 8 |
| Storage (GB) | 50 |
Considerations
Though having more cores is usually recommended, PHP, the primary language of the application only utilizes one core. It is recommended to have a large amount of RAM instead.
The latest version of Apache in conjunction with the latest version of PHP includes multicore support. Though this may seem like a recommendation, there is still proof in history that this typical LAMP structure is scalable especially with the proposed server architecture. We should consider multicore capabilities in the case of reducing the amount of needed instances and/or RAM. It is recommended to make the existing and stable technologies work before using the new ones as a crutch.
Database Server
The database cluster is primarily used to store objects and the relations between them. This acts as the original source of data where other data store constructs model off of. Other data store constructs mentioned later are used to help swiftly deliver data by using a flat structure however volatile in nature. The cluster strategy that we are going to use is Multi-Master Replication
Recommendations
A node cluster architecture is recommended because of it’s lack of single point stability. Each database server in this architecture is responsible for the synchronization of data evenly where by if one fails it will not effect the rest of the database layer. It’s recommended that a substantial amount of swap space is given per server in this cluster. It is also recommended that the database should not exceed it’s CPU utilization by 25% the ratio should be 1:1 means for every 1 database server only 1 application server should be connected into it. All the read operations should be redirected to an index server.
| Cores | 4 |
| Memory (GB) | 8 |
| Storage (GB) | 500 |
Considerations
Before vertically scaling it is recommended to horizontally scale first because synchronizing data between database servers still take time. Other considerations are to utilize a SANS or SSD as the storage for high performance, though costly at the same time.
Cache Server
The cache server is designed to deliver existing content faster than any index or relational database can perform. Caching has a crutch which requires content to actually be gathered initially before it is saved. Caching does not solve the performance for a unique request, but does solve it on consecutive requests.
Recommendations
A single server is recommended at first because of the nature of high availability and volatility. The application is designed to consider the failure of a cache server and by passes it on the occurrence. It’s recommended that a substantial amount of swap space is given per cache server.
Here are some reasons why we recommend having a dedicated cache servers within this architecture.
| Cores | 2 |
| Memory (GB) | 4 |
| Storage (GB) | 500 |
Considerations
Cache services have an out of box design to be clusterable>. We should consider clustering cache servers only if there is consistently a large amount of traffic for long periods of time and the hard drive of the cache server is running out.
Index Server
Index server is another kind of data store except it deals with a flat data structure based on the original relational database. Index services are optimized for both search and detail related pages. With that said, It’s important to always have a flat version of all data on hand at all times.
Recommendations
A single server is recommended at first because of the nature of high availability that an index service is designed to have. It’s recommended that a substantial amount of swap space is given per index server.
Here are the reasons why having an index server, preferably using Elastic Search is recommended for this architecture.
| Cores | 6 |
| Memory (GB) | 12 |
| Storage (GB) | 500 |
Considerations
Index services have an out of box design to be clusterable. We should consider clustering index servers only if there is consistently a large amount of traffic for long periods of time and the memory of the cache server is running out.
Worker Server
A worker server is primarily used to execute tasks in the job queue.
Recommendations
Four workers usually take up 1GB of memory and each job can vary between five seconds to one minute. Worker servers are usually manually balanced depending on how fast the queue grows and there is no out of box scalability feature for workers.
Here’s an overview why we recommend having a worker server in this architecture.
| Cores | 1 |
| Memory (GB) | 2 |
| Storage (GB) | 50 |
Considerations
The failure of a worker server only means that delayed tasks won’t execute. The simple resolution is to restart or spawn a new server in order to resolve the queue. This implies that failures of worker servers is a low risk event.
Queue Server
A job queue server is used for process that don’t necessarily need to be executed immediately. This introduces asynchronous features in the application that other languages naturally provide while adding on monitoring and resource management at the same time. Deciding on which business rules to delay will improves the user experience because response time will inherently be reduced with this technology.
Recommendations
A single server is recommended at first because of the nature of high availability and low resources that a queue service is designed to have. It’s recommended that a substantial amount of swap space is given per queue server.
Here’s an overview why we recommend having a queue server in this architecture.
| Cores | 6 |
| Memory (GB) | 12 |
| Storage (GB) | 500 |
Considerations
A single queue can process thousands of messages per second without requiring a lot of resources. On the rare occasion of failure queued tasks can be unrecoverable. Prevention is simply monitoring the size of the queue regularly. On the event of failure, a queue cluster needs to be considered. An alternative to hosting a queue server is using Amazon SQS however, costs are measured per API call.
3.C.2. Architecture Overview
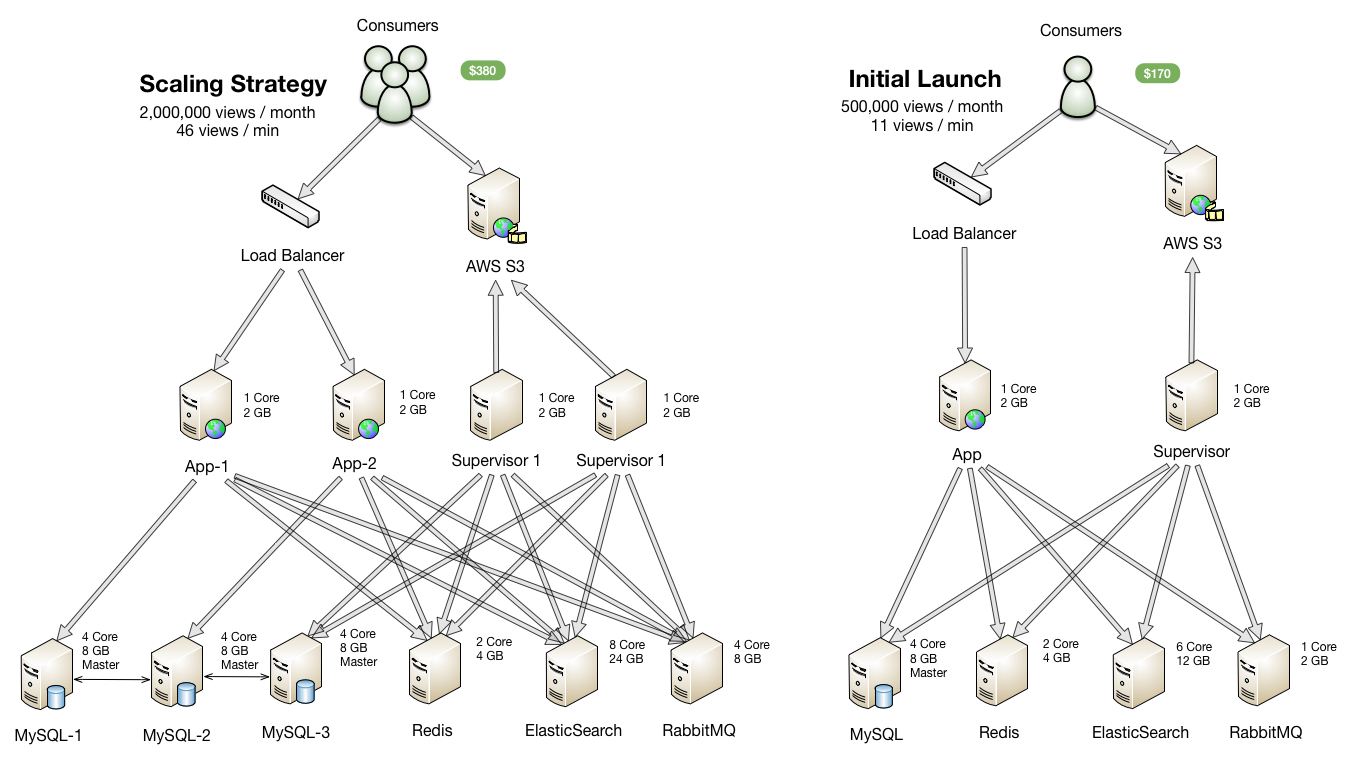
Most application launches only requires a minimum setup initially. Our goal here is to minimize the amount of servers needed, benchmarking a threshold of performance and ease the troubleshooting process.
The main understanding of this server architecture is one server per service. We don’t want to put the entire LAMP/LEMP stack in one server on purpose to understand how service performs.
App Server
We initially setup the load balancer to provision the case you need to scale application servers in the future. Otherwise you would need to account for DNS propagation.
Database Servers
Instead of clustering databases together to share the load, we assign one MySQL server per app server (and supervisor server). Then we sync the MySQL databases together using a master to master replica setup.
Since app servers are already balanced their assigned MySQL database would also be inherently balanced. With the ElasticSearch and Redis additionally covering the data requests, the database server would in theory be minimally used.
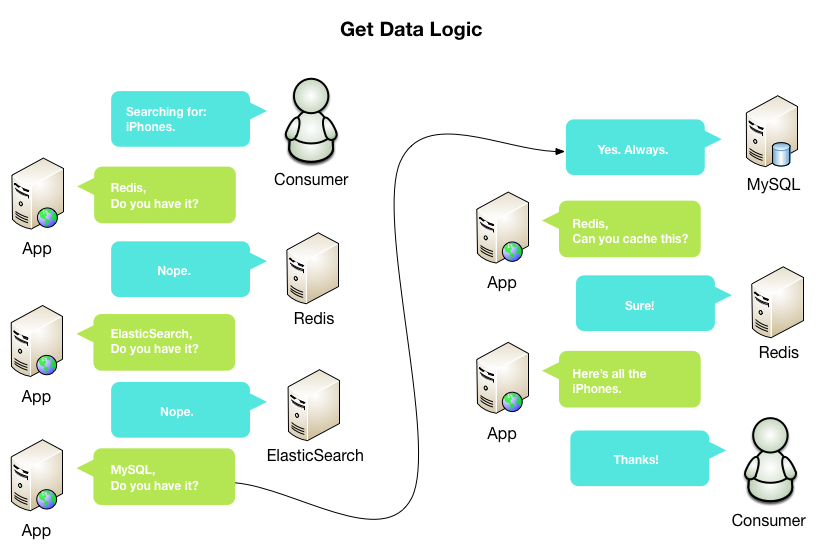
The following diagram explains how ElasticSearch and Redis helps distribute the data requests.
Queues
For tasks that require more server resources than normal (and takes some time), We recommend to queue these tasks instead of processing them on request. This will further reduce the amount of resources needed at any given time.
We use Supervisord on the worker servers to pull
tasks from the queue. Using the cradle-queue package we can start the worker
like the folowing example.
bin/cradle work
Ctrl+C to stop the worker
So Supervisord can use this same command to run in the background and multiple instances of this as well.
Between 4-8 workers can run on the recommended server specifications optimally
File uploading and S3
Instead of passing files to our app server, we rely on the client side to directly upload to S3. You can read about it here.